

Audyt techniczny SEO – co obejmuje analiza techniczna strony?
| Tomasz Sołtys | SEO/SXOTechniczny audyt SEO jest szczegółową analizą strony internetowej, która ma na celu zidentyfikowanie problemów wpływających na widoczność strony w wyszukiwarkach. Dobry audyt techniczny powinien obejmować wszystkie istotne obszary dla naszego SEO. Tak by można było na jego podstawie naprawić błędy techniczne i zoptymalizować stronę pod kątem wyszukiwarek. To przyczyni się do poprawy pozycji w wynikach wyszukiwania, zwiększenia ruchu i poprawy użyteczności dla użytkowników. Przyjrzyjmy się teraz po kolei poszczególnym obszarom, jakie powinien objąć audyt techniczny SEO.

Spis treści:
Stan indeksacji witryny
Indeksowanie witryny w Google to proces, dzięki któremu strony internetowe stają się widoczne dla użytkowników wyszukiwarki. Jest to zatem kluczowy proces, na którym opiera się widoczność w internecie, ponieważ tylko zindeksowane strony mogą pojawić się w wynikach wyszukiwania. Google wykorzystuje swoje boty (Googlebot) do przeglądania stron internetowych, odczytywania ich treści i dodawania do indeksu. Proces ten jest dynamiczny – nowe strony są ciągle dodawane, a stare aktualizowane lub usuwane z indeksu, w zależności od ich dostępności i jakości treści.
Aby zwiększyć szanse na indeksację powinieneś zapewnić łatwą nawigację, szybkość ładowania strony, unikalną i wartościową treść oraz odpowiednie użycie meta tagów. Regularne sprawdzanie stanu indeksacji za pomocą Google Search Console pozwala na bieżąco monitorować, które podstrony zostały zindeksowane, a które wymagają uwagi.
Inna, szybką metodą, żeby sprawdzić ile podstron Twojej witryny znajduje się w indeksie jest wpisanie w Google zapytania site:twojadomena.pl. W wynikach wyszukiwania Google pokaże przybliżoną liczbę podstron z Twojej witryny, które są zindeksowane.
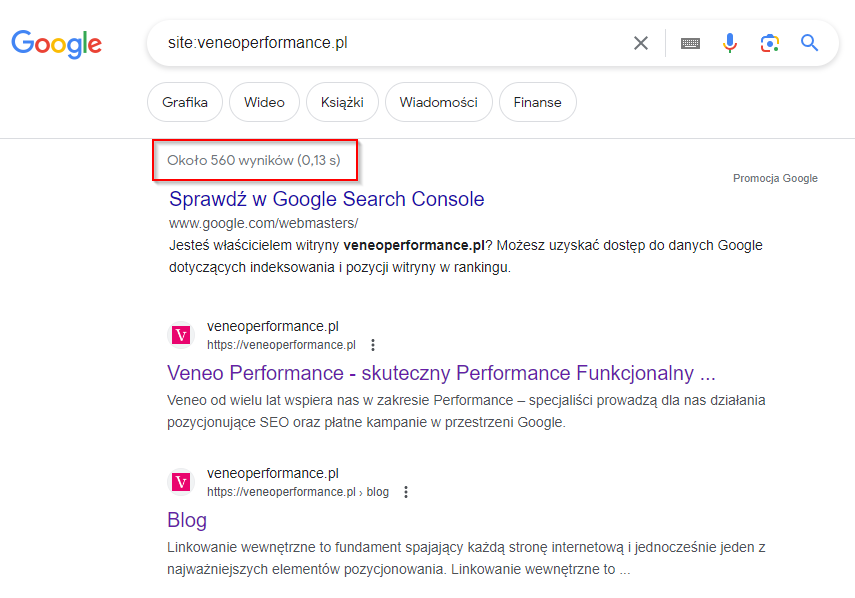
Rysunek 1 Wyniki dla zapytania site:veneoperformace.pl w Google.
Powinieneś zawsze dbać by wszystkie podstrony Twojej witryny znajdowały się z indeksie Google.
Wersja docelowa witryny
Każda strona internetowe może być dostępna pod wieloma adresami. Na przykład:
- twojadomena.pl
- www.twojadomena.pl
- http://twojadomena.pl
- https://twojadomena.pl
Jak widać powyżej strona może mieć kilka różnych wersji – wersję z subdomeną www, bez www,
z protokołem HTTPS lub bez). Istotne, aby wybrać wersję preferowaną i na nią ustawić przekierowania 301. Takie rozwiązanie zapobiegnie duplikacji w obrębie witryny.
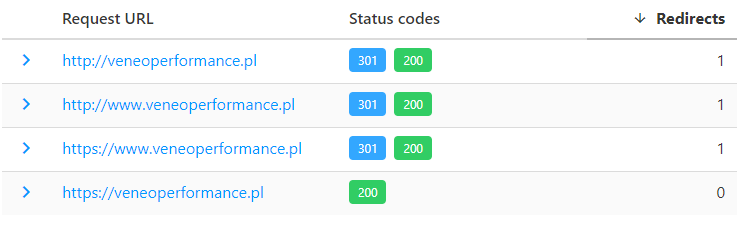
Rysunek 2 Kody odpowiedzi i przekierowania z narzędzia httpstatus.
Wersję naszej strony możemy sprawdzić narzędziem httpstatus.io. Jak widać preferowaną wersją domeny veneoperformace.pl jest https://veneoperformance.pl. Pozostałe wersje mają ustawione przekierowanie 301 na preferowaną. Wszystko jest zatem poprawnie.
Przekierowania 3XX
Przekierowania 3XX to grupa kodów odpowiedzi HTTP, które informują przeglądarkę internetową lub robota indeksującego, że dostęp do żądanej strony jest możliwy pod innym adresem URL. W ramach tej grupy najczęściej spotykane są przekierowania 301 (stałe) i 302 (tymczasowe).
Przekierowania 3XX mogą mieć znaczący wpływ na SEO, zarówno pozytywny, jak i negatywny, w zależności od sposobu ich implementacji.
Przekierowania 301 są interpretowane przez wyszukiwarki jako trwała zmiana adresu strony. Pozwalają one na zachowanie większości mocy SEO (tzw. link juice) przypisanej oryginalnemu adresowi URL, przekazując ją na nowy adres. Powinieneś użyć 301 przy trwałym przenoszeniu treści na nowy adres lub zmianie domeny.
Przekierowania 302 informują, że przeniesienie jest tylko tymczasowe. Wyszukiwarki zachowują oryginalny adres URL w swoich indeksach, co może nie przenieść pełnej mocy SEO na nowy adres.
Niewłaściwe użycie przekierowań, takie jak nadmierne stosowanie przekierowań 302 zamiast 301, może prowadzić do rozproszenia mocy SEO, a w skrajnych przypadkach — do pominięcia przez roboty indeksujące ważnych stron.
Unikanie przekierowań w linkowaniu wewnętrznym
Zarządzanie przekierowaniami jest równie ważne w kontekście linkowania wewnętrznego na stronie. W linkowaniu wewnętrznym należy unikać przekierowań. Z dwóch powodów. Po pierwsze, spowalniają ładowanie strony. Po drugie, rozpraszają moc linków (mogą nie przekazywać 100% link juice). Dlatego zaleca się bezpośrednie linkowanie do docelowych stron bez użycia przekierowań.
Błędy 4XX i 5XX
Błędy 4XX i 5XX są to kody statusu odpowiedzi HTTP, które informują o różnych rodzajach problemów napotkanych podczas próby dostępu do strony internetowej. Mają one bezpośredni wpływ na doświadczenia użytkowników oraz mogą wpłynąć na nasze SEO.
Błędy 4XX (błędy klienta)
Błędy 4XX wskazują na problemy po stronie klienta, czyli użytkownika próbującego uzyskać dostęp do strony. Najbardziej znanym kodem z tej serii jest błąd 404, oznaczający „Nie znaleziono” (Not Found), który pojawia się, gdy użytkownik próbuje uzyskać dostęp do strony, która została usunięta lub przeniesiona bez przekierowania.
Istotną kwestią jest również zadbanie o to by strona błędu 404 przekazywała jasny komunikat o błędzie dla użytkownika i dawała mu możliwość łatwego powrotu na naszą stronę.
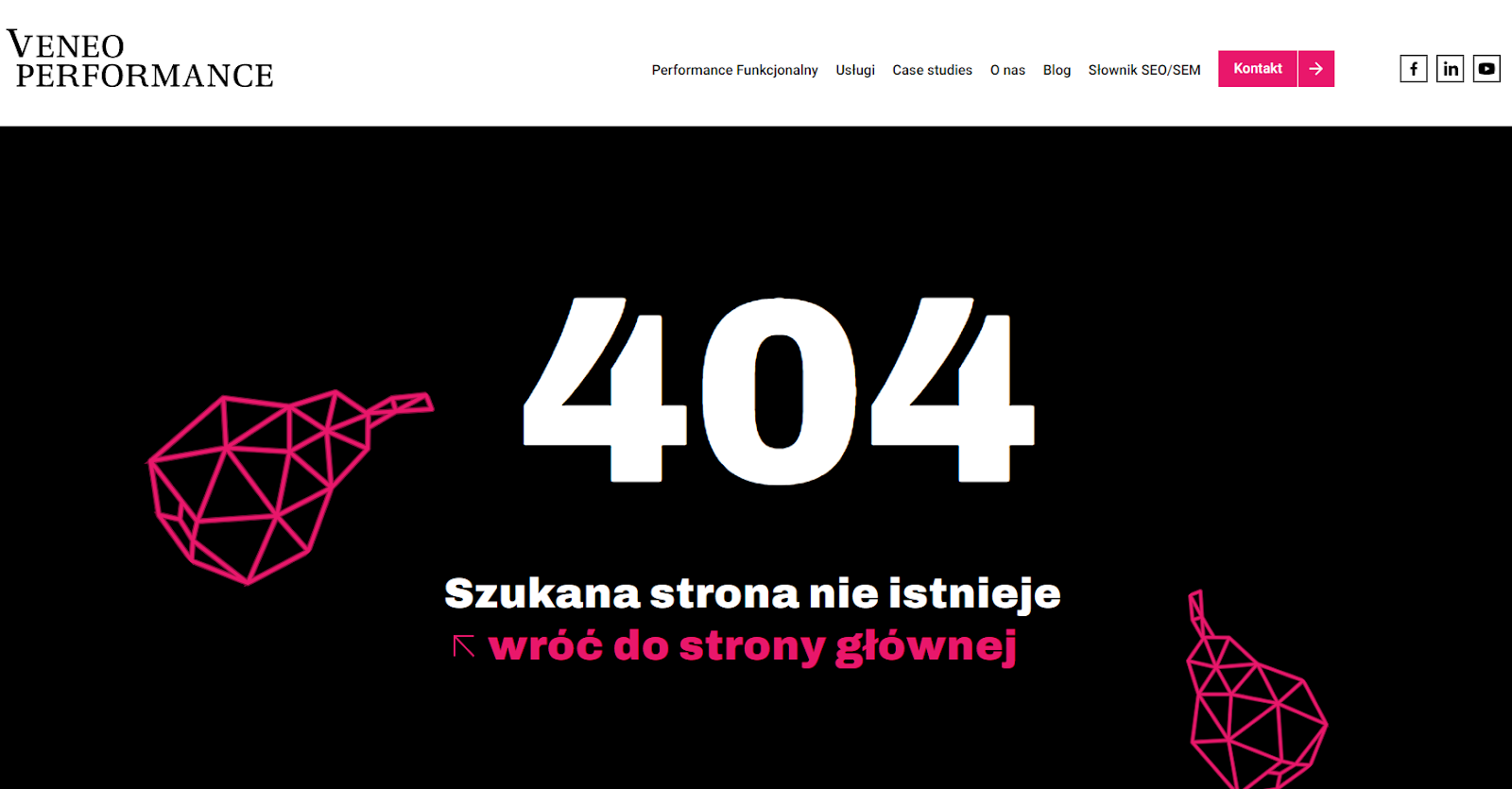
Rysunek 3 Strona 404 dla veneoperformance.pl.
Błędy 5XX (błędy serwera)
Błędy 5XX informują, że serwer napotkał sytuację, której nie potrafił obsłużyć, co uniemożliwia wyświetlenie Twojej strony. Najczęstsze błędy z serii 5XX to błąd 500 „Wewnętrzny błąd serwera”, który informuje, że serwer napotykał nieoczekiwany problem oraz błąd 503 „Usługa niedostępna”, który informuje, że serwer tymczasowo nie jest w stanie obsłużyć żądania z powodu przeciążenia lub prac konserwacyjnych.
Błędy 4XX i 5XX mają duży wpływ na SEO, ponieważ wyszukiwarki dążą do wyświetlania użytkownikom stron, które są dostępne. Strony z błędami mogą być postrzegane jako mniej wiarygodne lub nieaktualne, co negatywnie wpłynie na ich ranking w wynikach wyszukiwania. Unikanie błędów 4XX i 5XX jest zatem bardzo ważne dla SEO.
Meta tagi
Meta tagi to fragmenty kodu HTML, które dostarczają wyszukiwarkom oraz użytkownikom informacji o zawartości strony internetowej. Chociaż nie są widoczne bezpośrednio na stronie dla odwiedzających, odgrywają kluczową rolę w optymalizacji pod kątem wyszukiwarek. Najważniejsze meta tagi to:
Title tag (tytuł)
Title tag jest jednym z najważniejszych elementów SEO. Jest to tytuł strony wyświetlany w wynikach wyszukiwania oraz na karcie przeglądarki. Powinien być zwięzły i zawierać główne słowo kluczowe dla danej strony (najlepiej na początku). Dobrze zoptymalizowany title tag zwiększa CTR (click-through rate), czyli wskaźnik klikalności, co korzystnie wpływa na pozycjonowanie strony.
Meta description (opis)
Meta description to krótki opis strony, który również jest wyświetlany w wynikach wyszukiwania. Chociaż nie wpływa bezpośrednio na ranking strony w Google to jednak jest bardzo istotny dla CTR. Atrakcyjny i zwięzły opis, zawierający słowa kluczowe, może przekonać użytkownika do kliknięcia w nasz link. A strony z wysokim CTR są często lepiej oceniane przez algorytmy Google.
Robots meta tag
Ten tag pozwala kontrolować czy dane podstrony będą indeksowane oraz czy roboty wyszukiwarek mogą się po nich poruszać. Blokowanie indeksowania określonych stron jest przydatne dla treści, których nie chcemy indeksować w Google, np. strony z regulaminem czy polityką prywatności.
Poprzez atrakcyjne tytuły i opisy możemy znacząco wpłynąć na to, jak strona jest postrzegana przez użytkowników i algorytmy wyszukiwarek. W praktyce optymalizacja meta tagów wymaga równowagi między używaniem słów kluczowych a tworzeniem atrakcyjnych i zachęcających opisów dla użytkowników. To jak nasza strona wygląda w SERP (Search Engine Results Page) ma duży wpływ na to czy użytkownik ją wybierze i odwiedzi.
Struktura nagłówków na stronie
Hierarchiczna struktura nagłówków pomaga użytkownikom i algorytmom wyszukiwarek zrozumieć organizację treści na stronie. Nagłówek pierwszego poziomu, h1, powinien być używany do opisania głównego tematu strony – jest najważniejszym elementem tekstowym na stronie. Pozostałe nagłówki, od h2 do h6, służą do organizacji podsekcji treści w logicznej i hierarchicznej kolejności.
Nagłówek h1 powinien być unikalny dla każdej strony i zawierać główne słowo kluczowe, na które optymalizowana jest strona. Jest to pierwszy i najważniejszy widoczny element, na który zwracają uwagę algorytmy wyszukiwarek, aby zrozumieć tematykę strony.
Nagłówki h2 do h6 służą do dalszego dzielenia treści na sekcje i podsekcje, co ułatwia czytanie i nawigację. Odpowiednie używanie tych nagłówków i wplatanie w nie słów kluczowych może pomóc w poprawie rankingu strony dla tych fraz.
Najlepsze praktyki tworzenia nagłówków:
- Unikalność nagłówka h1 – zadbaj o unikalny nagłówek h1 dla każdej podstrony.
- Ilość nagłówków h1 – zadbaj by każda podstrona miała tylko jeden nagłówek h1.
- Logiczna kolejność – używaj nagłówków w sposób hierarchiczny i z zachowaniem kolejności, unikając pomijania poziomów (np. nie przechodź bezpośrednio od h1 do h3).
- Zawieranie sów kluczowych – wplataj słowa kluczowe w nagłówki, ale rób to naturalnie i z umiarem, aby uniknąć nadmiernego upychania fraz kluczowych.
- Krótko, zwięźle i na temat – pisz zwięzłe nagłówki, które bezpośrednio odnoszą się do zawartości sekcji, w którą wprowadzają.
Tagi kanoniczne
Tag kanoniczny to element HTML umieszczanym w sekcji nagłówka <head> strony internetowej. Jego zadaniem jest wskazanie wyszukiwarkom, która wersja danej strony jest preferowana do indeksowania, zwłaszcza w przypadku treści zduplikowanych lub bardzo podobnych.
W jakiej sytuacji należy stosować tagi kanoniczne? Na przykład, gdy na stronie występują różne wersje tej samej treści – produkty z identycznym opisem, różniące się jedynie parametrami URL. W takim przypadku stosowanie tagu kanonicznego pozwala wyszukiwarkom zrozumieć, która wersja powinna być traktowana jako oryginalna i pojawiać się z indeksie.
Dane strukturalne
Dane strukturalne to metadane dodawane do kodu strony internetowej, które pomagają wyszukiwarkom lepiej zrozumieć zawartość Twojej strony. Structural data pozwalają wyszukiwarkom wyświetlać bardziej szczegółowe i atrakcyjne wyniki, co z kolei może zwiększyć widoczność strony w wynikach wyszukiwania i poprawić CTR.
Wzbogacone wyniki wyszukiwania, generowane dzięki danych strukturalnym, mogą poprawić doświadczenia użytkownika, umożliwiając szybsze znalezienie potrzebnych informacji bez konieczności odwiedzania konkretnej strony.
Implementacja danych strukturalnych
Implementacje danych strukturalnych na stronie internetowej możesz wykonać na 3 sposoby – stosując format JSON-LD, RDF lub mikrodane. Najczęściej stosowanym formatem jest JSON-LD, ponieważ jest on łatwy do implementacji i zrozumienia zarówno dla ludzi, jak i dla robotów wyszukiwarek.
Jak sprawdzić czy Twoje dane strukturalne zostały prawidłowo zaimplementowane? Najlepiej skorzystać z narzędzia Google dostępnego pod adresem: https://search.google.com/test/rich-results?hl=pl
Rysunek 4 Narzędzie Google do testowania danych strukturalnych.
Warto zauważyć, że choć dane strukturalne nie są bezpośrednim czynnikiem rankingowym, mogą pośrednio wpływać na pozycję strony w wynikach wyszukiwania poprzez zwiększenie atrakcyjności i czytelności wyników wyszukiwania oraz poprawę doświadczenia użytkownika. Dlatego warto odpowiednio oznaczyć dane strukturalne na swojej stronie internetowej.
Zobacz także: Dane strukturalne – czym są i kiedy warto je wdrożyć?
Okruszki breadcrumbs na stronie
Okruszki (ang. breadcrumbs) to elementy nawigacyjne, które pełnią ważną rolę na stronie, szczególnie jeśli nasza strona ma „głęboką” strukturę treści, podkategorii czy produktów. Ich głównym zadaniem jest ułatwienie użytkownikom orientacji na naszej stronie. Dzięki breadcrumbs użytkownicy mogą łatwo śledzić swoją ścieżkę nawigacji od strony głównej aż po bieżącą lokalizację.
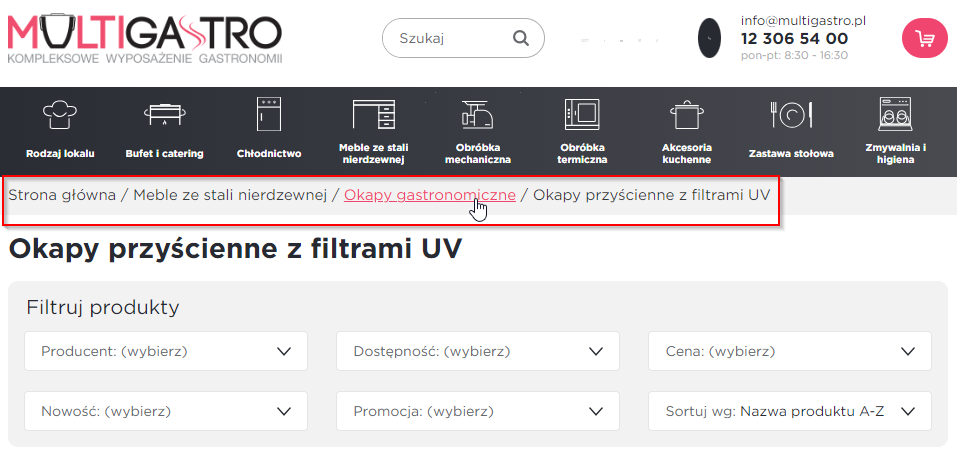
Rysunek 5 Nawigacja okruszkowa na stronie multigastro.pl.
Okruszki są często umieszczane na górze strony, poniżej paska nawigacyjnego, i prezentują ścieżkę w formie tekstowej, zwykle oddzielając poszczególne poziomy struktury strony za pomocą znaku większości (>) lub ukośnika (/). Na przykład: Strona główna / Kategoria / Podkategoria.
Jakie korzyści niesie wdrożenie nawigacji okruszkowej? Poza wspomnianą już ułatwioną nawigacją po stronie wdrożenie breadcrumbs ma jeszcze kilka zalet dla naszego SEO. Po pierwsze, ułatwiona nawigacja może prowadzić do większego zaangażowania użytkowników, co z kolei zmniejszy współczynnik odrzuceń. Po drugie, okruszki automatycznie generują linki wewnętrzne (najlepiej robić to tak by zawierały słowa kluczowe), które wspierają linkowanie wewnętrzne na stronie i pomagają wyszukiwarkom lepiej rozumieć strukturę witryny. Po trzecie, w breadcrumbs możemy dodać dane strukturalne, które dodatkowo wzbogacą nasze wyniki w Google. To uczyni je bardziej widocznymi i potencjalnie zwiększy CTR.
Struktura adresów URL i ich budowa
Na początek krótkie wprowadzenie i odpowiedź na pytanie co to jest adres URL? Adres URL to ciąg znaków, który wskazuje na konkretną lokalizację podstrony w sieci. Składa się z protokołu, nazwy domeny i ścieżki do podstrony. Przykładowo, w adresie URL https://twojadomena.pl/oferta, https:// to protokół, twojadomena.pl to nazwa domeny, a /oferta to ścieżka do konkretnej podstrony.
Aby adresy URL miały korzystny wpływ na SEO, ważne jest, aby były one jasne, logicznie zbudowane i przyjazne zarówno dla użytkowników, jak i dla wyszukiwarek.
Najlepsze praktyki budowania adresów URL:
- Zawieranie słów kluczowych – zadbaj o użycie słów kluczowych w adresach URL. To pomoże zrozumieć wyszukiwarkom, o czym jest dana strona, co korzystnie wpłynie na Twoje rankingi.
- Krótko i zwięźle – krótsze URLe są łatwiejsze do zapamiętania i wpisywania dla użytkowników, a także lepiej wyglądają w wynikach wyszukiwania.
- Używanie myślnika do rozdzielenia słów – myślniki są uznawane za „spacje” w adresach URL i pomagają zarówno użytkownikom, jak i wyszukiwarkom w rozumieniu adresów. Unikaj używania podkreślników, czy innych znaków specjalnych.
- Utrzymywanie logicznej struktury – utrzymuj hierarchiczną strukturę w swoich URLach. Na przykład, jeśli masz sklep internetowy, struktura URLi powinna odzwierciedlać kategorie i podkategorie produktów.
- Używanie małych liter – wiele serwerów rozróżnia wielkość liter, użycie dużych może prowadzić do problemów z dostępnością lub duplikacją treści. Stosuj wyłącznie małe litery w adresach URL by uniknąć takich problemów.
- Unikanie niepotrzebnych parametrów – parametry URL, takie jak np. parametry produktów, mogą utrudniać indeksowanie stron i sprawiać, że URL jest bardziej skomplikowany. Unikaj ich używania lub ogranicz do koniecznego minimum.
- Unikanie rozszerzeń plików – najlepiej pomijać wszelkie rozszerzenia plików (jak .html, .php). w adresach URL – będą wtedy bardziej przyjazne i estetyczne.
Optymalizacja grafik
Optymalizacja grafik pod kątem SEO jest to kolejny ważny element poprawy widoczności Twojej strony internetowej w wynikach wyszukiwania. Na początek zwróć uwagę na odpowiedni format grafik i ich rozmiar. Najpopularniejsze formaty to JPEG (dla zdjęć i grafik), PNG (dla grafik z przezroczystością) oraz WebP (zalecany format przez Google, zapewnia znaczne oszczędności rozmiaru pliku przy zachowaniu jakości). Zanim umieścisz grafikę na stronie, użyj narzędzi do kompresji grafik, które zmniejszają rozmiar zdjęcia bez znaczącej utraty jakości. To poprawia czas ładowania strony, co jest ważnym czynnikiem rankingowym.
Kolejne aspekty, na które powinniśmy zwrócić uwagę optymalizując grafiki na naszej stronie to nazwy plików graficznych oraz atrybuty alt. Zarówno w jednym jak i drugim przypadku powinniśmy używać opisowych nazw, które zawierają słowa kluczowe. Przykładowo, dobrą nazwą grafiki będzie „czerwony-samochod-audi-a6.jpg”. A odpowiednim altem takiej grafiki tekst „czerwony samochód audi a6”.
Warto również zwrócić uwagę na sposób ładowania grafik. Powinniśmy korzystać z techniki lazy loading, która pozwala na ładowanie grafik dopiero wtedy, gdy znajdują się one na ekranie widocznym dla użytkownika. Takie rozwiązanie przyspiesza czas ładowania strony.
Grafiki dobrze jest oznaczyć za pomocą danych strukturalnych, warto również zadbać o ich wyświetlania na urządzaniach mobilnych. Na koniec, szczególnie jeśli Twoja strona zawiera dużo ważnych grafik, rozważ utworzenie i zgłoszenie mapy obrazów do Google. Pozwoli to na lepsze indeksowanie zawartości graficznej Twojej strony.
Duplikacja w obrębie witryny
Duplikacja wewnętrzna ma miejsce gdy w obrębie jednej witryny internetowej pojawiają się identyczne lub bardzo podobne treści na różnych podstronach. Tego typu duplikacja będzie mieć negatywny wpływ na SEO i jest zjawiskiem, którego należy zdecydowanie unikać.
Duplikacja wewnętrzna wiąże się z kilkoma zagrożeniami. Po pierwsze i najważniejsze, będzie generować problemy z indeksowaniem. Google będzie może mieć trudności z zaindeksowaniem stron ze zduplikowaną treścią. I najprawdopodobniej część treści nie zostanie w ogóle uwzględniona w wynikach wyszukiwania. Kolejny problem to zmniejszenie mocy linków – w przypadku, gdy kilka stron zawiera identyczną treść, linki zewnętrzne mogą prowadzić do różnych wersji tej samej strony, a to osłabi potencjał rankingowy każdej z tych stron. Ostatnia kwestia, to słabsze user experience. Duplikacja wewnętrzna może wprowadzać użytkowników w błąd i sprawiać, że trudniej jest im znaleźć poszukiwane informacje.
Jak uniknąć duplikacji wewnętrznej?
Przede wszystkim upewnij się, że treści w obrębie Twojej witryny są unikalne. Jeżeli publikujesz bardzo podobne treści korzystaj z tagu canonical, dzięki czemu wskażesz Google preferowaną wersję strony. Ponadto, upewnij się, że prawidłowo korzystasz z parametrów w adresach URL – często duplikacja treści wynika z różnych parametrów URL, które prowadzą do tej samej treści. Ostatnia kwestia, jeśli Twoja strona jest dostępna w kilku językach, upewnij się, że korzystasz z odpowiednich atrybutów hreflang, aby wskazać wyszukiwarkom powiązanie między wersjami językowymi.
Błędy kodu HTML, CSS i Java Script
Błędy kodu HTML, CSS i Java Script mogą wpłynąć na sposób, w jaki użytkownicy wchodzą w interakcję ze stroną, w tym na czas spędzony na stronie, liczbę odwiedzanych stron oraz na interakcje z elementami strony. Te wszystkie czynniki będą brane pod uwagę przez algorytmy rankingowe.
Błędy w HTML mogą utrudnić robotom wyszukiwarek zrozumienie struktury i zawartości strony. Na przykład, niepoprawne użycie tagów nagłówków (h1, h2 itd.) może wprowadzić zamieszanie co do hierarchii i znaczenia treści.
Błędy w CSS mogą wpływać na sposób wyświetlania strony, co z kolei może negatywnie wpłynąć na doświadczenia użytkowników. Strony źle wyglądające lub trudne w nawigacji są często szybko opuszczane przez użytkowników, co zwiększa współczynnik odrzuceń.
Błędy w JavaScript mogą znacząco spowolnić ładowanie i działanie strony. Google i inne wyszukiwarki premiują szybkie strony, ponieważ szybkość ładowania jest ważnym czynnikiem UX.
Regularne monitorowanie i poprawianie błędów w kodzie naszej witryny jest bardzo istotne dla utrzymania i poprawy pozycjonowania strony w wynikach wyszukiwania.
Prędkość ładowania witryny
Google i inne wyszukiwarki dążą do zapewnienia użytkownikom jak najlepszego user experience, a szybkość ładowania strony jest nieodłącznym czynnikiem UX. Witryny, które ładują się wolno, mogą być gorzej oceniane przez algorytmy rankingowe, co skutkuje niższą pozycją w wynikach wyszukiwania.
Rysunek 6 Narzędzie Google do sprawdzania szybkości ładowania strony.
Aby poprawić prędkość ładowania witryny, można podjąć takie działania jak:
- Optymalizacja obrazów
- Wykorzystanie cache przeglądarki
- Minimalizacja kodu
- Wykorzystanie CDN (Content Delivery Network)
- Optymalizacja CSS i JavaScript
- Optymalizacja serwera
- Wykorzystanie lazy loading
Nie będę szerzej opisywał każdego z tych aspektów. Jeśli jednak jesteś zainteresowany bardziej szczegółowymi informacjami to uzyskasz je korzystając z narzędzi do monitorowa prędkości ładowania strony. Jakimi narzędziami sprawdzić prędkość ładowania strony? Polecam użyć: Google PageSpeed Insights i GTmetrix.
Wersja mobilna strony
Odkąd Google i inne wyszukiwarki przeszły na Mobile-First Index (co oznacza, że to wersja mobilna strony jest podstawą do oceny i indeksowania treści przez wyszukiwarki) tym bardziej musisz zadbać aby Twoja strona prawidłowo działała na urządzeniach mobilnych. Ale przecież nie chodzi tylko o wyszukiwarki. Drugi, równie ważny powód, by zadbać o responsywną stronę to stale rosnąca ilość użytkowników ruchu mobilnego. Jeśli Twoja strona nie jest przystosowana do potrzeb urządzeń mobilnych, ryzykujesz utratę bardzo znacznej ilości odwiedzających.
Strona mobilna, która jest szybka, łatwa w nawigacji i przyjazna użytkownikowi, przyczynia się do lepszego user experience. A to będzie sygnałem dla wyszukiwarek, że Twoja strona jest wartościowa, co korzystnie wpłynie na pozycjonowanie. Strony mobilne, które są zoptymalizowane pod kątem szybkości ładowania, użyteczności i dostępności treści generują lepsze współczynniki zaangażowania, takie jak niższy współczynnik odrzuceń, dłuższy czas spędzony na stronie i większa liczba odwiedzanych stron. A lepsze współczynniki zaangażowania to lepsza ocena naszej strony przez algorytmy wyszukiwarek.
Dostęp robotów – robots.txt
Plik robots.txt określa, które części witryny mogą być przeszukiwane przez roboty oraz te, do których roboty nie mają dostępu. Plik robots.txt powinien być umieszczony w głównym katalogu witryny – np. veneoperformance.pl/robots.txt. Roboty wyszukiwarek sprawdzają ten plik przed przeszukaniem zawartości witryny, aby upewnić się, że działają zgodnie z określonymi tam wytycznymi.
Plik robots.txt składa się z rekordów, które określają polecenia robotów wyszukiwarek. Każdy rekord składa się z co najmniej jednej linii User-agent, która określa robota wyszukiwarki, do którego odnoszą się dyrektywy oraz jednej lub więcej dyrektyw Disallow lub Allow, które określają, które foldery są zablokowane lub dozwolone dla danego robota.
Przykład:
- User-agent: *
- Disallow: /login/
W tym przykładzie, dyrektywa User-agent: * oznacza, że zasady dotyczą każdego robota. Dyrektywa Disallow wskazuje na to, że folder /login/ nie może być indeksowany przez wszystkie roboty.
Jakie roboty można zablokować w robots.txt? Roboty praktycznie wszystkich wyszukiwarek (np. Googlebot, Bingbot) oraz roboty narzędzi SEO – jak na przykład Majestic (MJ12Bot) czy Ahrefs (AhrefsBot).
Mapa witryny – sitemap. xml
Plik sitemap.xml to dokument w formacie XML, który służy do informowania wyszukiwarek internetowych o dostępnych do zaindeksowania stronach na danej witrynie. Zawiera on listę adresów URL do podstron w witrynie, a czasami dodatkowe informacje o każdym z nich, takie jak np. data ostatniej aktualizacji. Dzięki temu wyszukiwarki mogą łatwiej i szybciej przeszukiwać witrynę oraz indeksować nowe podstrony.

Rysunek 7 Fragment mapy witryny dla strony veneoperformance.pl.
By Twoja mapa witryny jeszcze lepiej spełniała swoją rolę w wyszukiwarce Google powinieneś ją zgłosić w Google Search Console w zakładce Mapy witryn.
Jak mapa strony wspomaga indeksowanie i SEO? Dzięki plikowi sitemap.xml roboty indeksujące, takie jak Googlebot, mogą łatwiej odkrywać i szybciej indeksować wszystkie podstrony na Twojej witrynie. Jest to szczególnie ważne dla nowych stron internetowych lub dla tych, które regularnie dodają nowe treści. Stale aktualizowana o nowe adresy mapa sitemap.xml sprawi, że wyszukiwarki szybko znajdą i zaindeksują te nowe lub zaktualizowane podstrony.
A dlaczego w ogóle powinieneś dbać by wszystkie podstrony w obrębie Twojej witryny była zaindeksowane? Tylko zaindeksowane strony mogą pojawiać się w wynikach wyszukiwania. Dlatego im więcej masz zaindeksowanych podstrony tym większa będzie widoczność Twojej witryny w internecie. A do tego przyda Ci się właśnie mapa sitemap.xml.