

Co to jest Crawl Budget?
| Veneo Performance | SEO/SXODo zrozumienia pojęcia Crawl Budget musimy zacząć od odmówienia procesów wchodzących w jego skład, a są to: crawl rate limit, crawl demand, planowanie.

Spis treści:
Crawl rate limit
Crawl rate limit jest to współczynnik skanowania. Jest on określany przez Googlebot’a na podstawie możliwości serwera strony, w ten sposób, aby nie obciążać jej zbytnio i nie powodować jej spowolnienia, a przez to pogorszyć doświadczenia z użytkowania strony. Crawl Rate zmienia się bazując na 2 czynnikach:
- Crawl health: jeśli strona odpowiada szybko wtedy limit współczynnika skanowania wzrasta, jeśli sytuacja jest odwrotna i strona spowalnia, lub nie odpowiada wtedy limit ten spada.
- Limit Ustawiony w Search Console: istnieje możliwość zmniejszenia limitu skanowania, lecz zwiększenie go nie oznacza, ze automatycznie nasza strona będzie skanowana częściej.
Crawl Demand
Ten czynnik określa jak dużo i jakie strony będą odwiedzone i zaindeksowane podczas jednego przejścia bota. Googlebot określa które adresy URL są ważniejsze i umieszcza je jako pierwsze w kolejce do indeksacji. Ważność adresów określana jest na podstawie 2 czynników:
- Popularność: jeśli adres jest często linkowany i udostępniamy w Internecie, będzie postrzegany jako ważniejszy, a przez to będzie miał większą szansę na przeskanowanie.
- Świeżość: jeśli często aktualizujemy zawartość naszej strony, wtedy mamy większa szanse na bycie przeskanowaną przez robota Google, ponieważ świeża zawartość jest lepiej postrzegana niż taka, która nie była aktualizowana od dłuższego czasu.
Planowanie
Proces skanowania jest złożony i wymaga stworzenia listy adresów, które będą skanowane na danej stronie. Lista ta nie jest ułożona w sposób przypadkowy i zależy od wyżej wymienionych czynników, które determinują kolejność skanowania.
Czy Crawl Budget jest ważny?
Crawl Budget jest czymś o co powinny się obawiać głownie duże strony, zawierające więcej niż kilka tysięcy adresów URL, jak np. duże sklepy e-comerce. Może to powodować ze nie wszystkie strony zostaną przeskanowane przez robota, a to z kolei może mieć wpływ . Dla tego tak ważne jest włączanie z indeksacji stron, które są nieaktualne lub nie ma potrzeby ich skanowania (jak strony kategorii produktów).
W przypadku mniejszych stron nie ma konieczności przejmowanie się tak bardzo Crawl Budgete’em ze względu na ilość adresów URL, które muszą być zaindeksowane. Większym problemem w takim przypadku mogą być błędy na stronach powodujące spadek szybkości skanowania stron.
Sprawdzamy jak roboty skanują naszą stronę
Do optymalizacji Crawl Budget’u, najpierw musimy poznać problemy, z jakimi boryka się strona i jaki mają one wpływ na crawl budget.
Jednym z podstawowych narzędzi do ocenienia kondycji strony jest Google Search Console. Za pomocą tego narzędzia możemy sprawdzić ilość aktualnie zaindeksowanych stron, ile z nich zostało wykluczonych i jaki był tego powód, oraz czy występują błędy, które mogą wpływać na crawl budget.
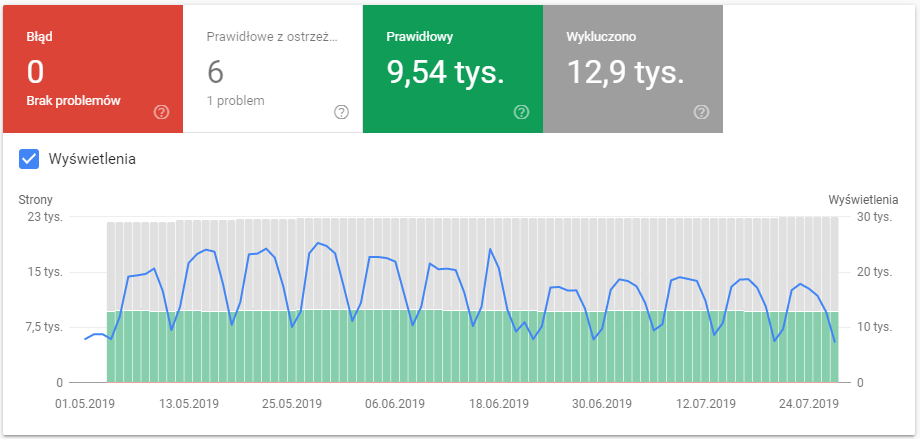
Google Search Console
Kolejnym sposobem na sprawdzenie co dokładnie jest skanowane przez robota Googl’a, jest analiza logów serwera. Podczas przeglądania tych danych sprawdzimy, czy skanowany kontent jest dla nas ważny, czy wręcz przeciwnie.
Podczas analizy logów serwera powinniśmy sprawdzić:
- kody odpowiedzi: poprawnie jest, kiedy strona zwraca głównie kody 200 i 301. Jeśli inne kody występują z dużą częstotliwością, powinniśmy być zaalarmowani i podjąć działania mające na celu zmianę tej sytuacji.
- najczęściej skanowane strony: powinniśmy sprawdzić, które z naszych stron są najczęściej odwiedzane przez Googlebota. W idealnym wypadku najczęściej skanowane powinny być strony z najważniejsza dla nas zawartością.
Jako właścicielowi strony powinno nam zależeć na tym, aby jak największa ilość stron znajdowała się w indeksie Google. Ułatwia to potencjalnemu użytkownikowi znalezienie naszej strony.
Jak zoptymalizować Crawl Budget?
Stosowanie pliku robots.txt to dobra praktyka w działaniach SEO. W tym pliku wyłączamy ze skanowania przez robot te sekcje naszej strony, które nie muszą być przeskanowane jak strona logowania czy strona z regulaminem. Stworzenie mamy strony także jest bardzo pomocne przy zarządzaniu Crawl Budgetem. W pliku sitemap.xml zamieszczamy wszystkie adresy zwracające poprawny kod 200, zawierające tagi index i follow, strony kanoniczne. Tak stworzona mapa strony powinna być wysłana do Googl’a za pomocą Google Search Console. Dobrze jest zamieścić link do mapy strony w pliku robots.txt.
Innym sposobem jest używanie tagu noindex. Stosowanie tego tagu powoduje, ze robot przeskanuje ale nie zajdzie indeksowanie strony w Googlach.
Co wpływa na Crawl Budget?
JavaScript: duża ilość kodu JavaScript na stronie może mieć negatywny wpływ na Crawl Budget. Jest to spowodowane tym, ze renderowanie kodu JS jest bardziej złożone od renderowania kodu HTML, przez co wymaga więcej pracy do przebrnięcia przez kod JS, co spowalnia proces skanowania strony. Może być to dla nas szczególnie istotne, jeśli często aktualizujemy zawartość strony, która jest ukryta pod JavaScripte’em.
Sposobem na poradzenie sobie z tym problemem jest wprowadzenie dynamicznego renderowania.
Niska wydajność: jeśli nasza strona nie jest najlepiej zoptymalizowana i miewa problemu z szybkością odpowiedzi serwera, ilość wizyt Googlebota będzie spadać. Żeby temu zapobiec możemy podjąć pewnie działania:
- Zmniejszenie TTFB: Time To First Bite jest do opóźnienie pomiędzy wysłaniem zapytania, a otrzymaniem odpowiedzi od serwera. Najprostszym rozwiązaniem na zmniejszenie tego współczynnika jest zastosowanie pamięci podręcznej po stronie serwera.
- Sprawdzenie optymalizacji witryny: istnieje wiele narzędzi do testowania wydajności naszej strony w sieci. Jednym z nich jest PageSpeed Insights gdzie po wprowadzeniu adresu strony otrzymujemy wyniki szybkości naszej strony na komputerach i urządzeniach mobilnych. Dostajemy także informacje na temat tego, które elementy nasze strony najbardziej wpływają na szybkość renderowania.
Wewnętrzne przekierowania: duża ilość przekierowań w serwisie może spowodować problemy ze skanowaniem naszej strony przez robota. Dla tego powinniśmy unikać łańcuchów przekierowań. By sprawdzić czy na naszej stronie występują takowe przekierowania możemy użyć narzędzi jak ScreamingFrog czy DeepCrawl. Za pomocą tych programów możemy manualnie przeskanować stronę w poszukiwaniu błędów, a po ich zidentyfikowaniu poprawić je.
Duplikaty stron: powinniśmy unikać duplikowania zawartości stron w naszej witrynie, ponieważ może mieć to wpływ na Crawl Budget. Sposobem na to jest stosowanie tagów kanonicznych, które wskazują na to, który adres URL jest adresem oryginalnym.
Wewnętrzne Linkowanie
Wewnętrzne linkowanie pomaga w poruszaniu się po stronie, a dobrze zbudowana struktura linków pomaga w skanowaniu ważnej dla nas zawartości. Brak wewnętrznego linkowania może powodować z niektóre segmenty naszej strony nie będą skanowane przez robota Googla. W trakcie tworzenia struktury linków na stronie musimy uważać ma kilka rzeczy:
- linkowanie do stron z błędami 404: sprawdź czy nie wysyłasz googlebota na nieistniejące strony
- strony które są obecne w sitemapie, ale nie są linkowane wewnętrznie
- strony z długą ścieżka kliku: upewnij się ze większość zawartości jest dostępna w mniej niż 3 kliknięciach
Błędy w sitemapie lub jej brak.
Brak sitemapy lub jej błędna implementacja mogą prowadzić do problemów ze skanowaniem. Dla tego powinniśmy zadbać, aby mapa naszej strony była regularnie aktualizowana i nie posiadała błędów.
Czego nie powinniśmy umieszczać w sitemapie?
- adresów URL zwracających kody inne niż 200,
- adresy blokowane przez plik robots.txt,
- strony paginacji,
- adresy zawierające tagi: noindex, follow; noindex,nofollow;
Zarządzanie Crawl Budget’em może okazać się bardzo istotne, w sytuacji gdy posiadamy duża witrynę ze sporą ilością podstron. Wtedy dbanie o crawl budget może być bardzo pomocne w kontekście osiągania dobrych wyników przez naszą stronę. W przypadku mniejszych stron nie ma to aż takiego znaczenia, lecz zawsze warto starać się by nasza strona była w dobrej kondycji.